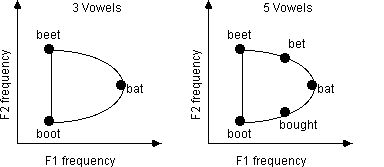
| A list of some basic properties | Best option |
| a. Serif vs. sans-serif: A serif is the little
horizontal
mark on the tops and bottoms of vertical lines in fonts (the line on
the
bottom of this f). Originally, it was used when cutting letters
in
stone to prevent the stone from cracking, but it was preserved out of
tradition.
Luckily, serif is better. b. Weight difference: Some lines in a character are thicker than others (e for example). c. Bias: The fonts can be on a bias or they can be vertical. d. x-height: How much height is devoted to the body of the characters (how tall the x is). e. Spacing: Some characters are wider than others (i vs. e). Typewriters force these to take up the same amount of space, but it's not required in printing (proportional is when they take up only the required space) (piece vs. piece). f. Proportions: How big is the x-height relative to the heights of ascenders and descenders (parts going above and below the body of the letter). There is an optimal proportion for each font. |
Serif Difference Biased More is better Proportional Optimal |
| N N Z N Z N Z N Z Z N Z Z N Z Z N N N N N Z N X N Z N N N Z N Z N Z N Z Z N Z Z N Z Z N N |
O O P O P O P O P P O P P O P P P O O O P P O X P O P O O P O P O P O P P O P P O P P P O |
| See | Choose |
| d | d or k? |
| See | Choose |
| word | d or k? |
| See | Choose |
| rwod | d or k? |