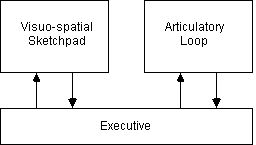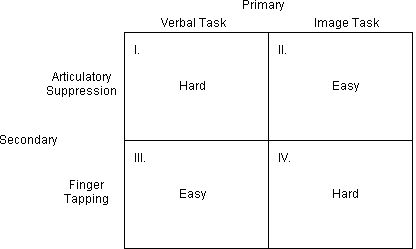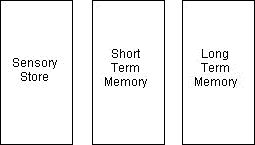
| # Int Items | List | Target | Response |
|
1 5 9 3 7 11 |
Slow examples:
9 5 8 4 7 9 8 1 4 3 3 4 8 7 6 9 5 5 9 9 6 8 5 4 2 6 1 2 8 5 6 7 5 2 4 5 5 9 7 3 9 4 9 4 1 2 3 5 Fast examples: 7 7 3 1 4 6 8 6 8 3 7 1 2 8 9 7 2 1 9 6 7 8 9 5 4 6 7 5 6 9 2 3 1 9 3 2 8 4 4 3 2 9 9 4 6 2 5 1 |
6 1 7 2 4 8 |
9 2 3 8 6 4 |
| List 1 | List 2 | List 3 | List 4 |
| banana
peach apple |
plum
apricot lime |
melon
lemon grape |
orange
cherry pineapple |
| 278 | 436 | 322 | 184 |
| List 1 | List 2 | List 3 | List 4 |
| banana
peach apple |
plum
apricot lime |
melon
lemon grape |
doctor
teacher lawyer |
| 278 | 436 | 322 | 184 |