Langston, Cognitive
Psychology, Notes 6 -- Episodic Long Term Memory
Note: Some of the memory demonstrations that we will do in class
will be messed up if you have advance knowledge of them. I
encourage
you to preview the notes before class, but try to skip the parts about
the memory demonstrations.
I. Goals.
A. Where we are/themes.
B. The processes.
C. The parts.
D. Segue into a new idea.
II. Where we are/themes.
A. Here are some situations:
1. Why is it sometimes so hard to remember things after you study
them? Why do you remember some things really well, but other
things
not as much when you study them in the same session?
(I have some questions for you about this class.)
2. There's a lot of stuff that I know for a fact I learned at
some point in my life. For example, I got a B in Calculus.
I must have known some calculus back then. Now, I can’t remember
a thing. Why?
B. Where we are. Remember, we’re working our way through
this box model of the mind. We’ve talked about the sensory
register.
The register holds information briefly, and pattern recognition figures
out what the information is. We also looked at attention.
Last
time we looked at brief memories in short-term memory. Now we
turn
our attention to long-term memory. What is long-term memory and
how
do you use it?
 Long-term memory: A permanent memory store with unlimited
capacity
that acts as a store for everything you know.
Long-term memory: A permanent memory store with unlimited
capacity
that acts as a store for everything you know.
C. Themes.
1. One long-term memory or many? The evidence indicates
that there are three or four. These could be different kinds of
memory,
or different kinds of processes. We’ll discuss the evidence for
that.
Top
III. The processes. Two basic things: Encoding
(getting stuff in) and retrieval (getting stuff out). In a way,
these
two aren’t really independent (as in “if it’s not encoded it can’t be
retrieved”).
Let’s treat them as separate anyway.
CogLab: To start things
off, we'll look at the data from our serial position demonstration.
A. Encoding: What affects it?
1. What you do with the material. You have lots of control
processes that you can use to get material from short-term memory to
long-term
memory. Different strategies work better for different people,
and
different strategies work better in different situations.
a. Rehearsal (repetition). This is probably everyone’s
favorite mode of learning a list. As you hear each item you
repeat
it and some other items over and over. This leads to two
predictions.
First, the more times you rehearse something, the better you should
remember
it. Second, the more items that come along after the last
rehearsal
of an item the worse memory should be (Atkinson & Shifrin,
1968).
If rehearsal is the primary mechanism of getting material from
short-term
memory to long-term memory then we should see effects of manipulating
rehearsal.
1) Glanzer and Cunitz (1966) again. Last time we looked
at how a 30 second period of counting backwards messed up the recency
part
of a serial position curve. Speeding up the
presentation
of the list caused primacy to go down.
2) Rundus (1971). As people learned a list of words, Rundus
asked them to rehearse out loud. They could rehearse any words
they
wanted to, but it had to be out loud. Rundus compared the number
of rehearsals to recall probability and found that more frequent
rehearsal
led to better recall.
3) Fischler, Rundus, and Atkinson (1970). Make people
rehearse
only the item being presented. Primacy goes away because every
item
gets the same amount of rehearsal.
b. Mnemonics (coding). Besides rehearsal, you can try a
number of other memory tricks to get information to transfer (some of
these were discussed in the imagery unit). You
might know that HOMES tells you the name of the great lakes. I
still
remember the number of Metro in Houston because in 1986 when I was
helping
my brother move they kept playing a commercial saying the number was
“Dixie,
drive your cows in” (635-4000). My locker combination is
“toothpicks
are so dirty” (26-0-30). In the next unit of the class, we’ll
look
at other techniques to improve transfer and see why they work.
c. Visual images. Some people are good verbal learners,
some are better with images. There is evidence that bizarre
imagery
can have a large effect on improving memory. The trick is to
imagine
each item in a list interacting with other items in some creative way
(again, check the imagery notes).
2. How you structure your control processes. There are
three basic tasks involved: Allocate attention to the task, do
some
processing, decide when you’ve learned it (when to stop).
Atkinson
(1972) had three kinds of learners. One group received a
randomized
list of items. Each time a German word was presented, they wrote
the English translation. Since the list was random, some of the
things
they rehearsed were already well-learned, and some were not learned at
all. A second group got to choose what to study. If people
optimize their learning strategy, then they’ll spend more time studying
what they don’t know.
The interesting group for Atkinson was one for which a computer
controlled
the training. Atkinson theorized that there are three kinds of
items
when you’re in the process of learning. Some items you don’t know
at all (unlearned), some you really know (learned), and some are in
transition
(temporary). If you rehearse, you should rehearse what’s
temporary
or unlearned, not what you know. The computer was programmed to
pick
only what was not learned. Atkinson wanted to compare this group
(optimal) to people choosing for themselves and people rehearsing at
random.
You can see the results here. The optimal group did the worst
in training, but had the best recall one week later. The random
group
did the best in training, but had the worst recall. Why?
The
optimal group only studied what they didn’t know. This means they
made a lot of mistakes in training, but they were learning more.
The random group wasted a lot of rehearsal, and they didn’t learn as
much.
The group that chose their own rehearsals was in between. They
did
better than random, but not as good as optimal.
You might keep this in mind as you study for the exam. Try to
learn what you don’t know yet, spend less time on what’s learned.
This is also related to when you should stop studying. A lot of
people
stop too soon. Glenberg, Sanocki, Epstein, and Morris (1987)
looked
at calibration of comprehension. This is how well people think
they
know material compared to how well they actually know it. When
people
read a story and were then asked to rate how confident they were that
they
could recognize a statement from that story, there was no relationship
between confidence and accuracy. This phenomenon is prevalent
with
a wide range of learning tasks and tests. What it means is that
people
rarely know whether what they know will be good enough for a
test.
Something else to consider as you study.
In answer to our first question, the reason you remember some things
better might have something to do with the amount of rehearsal.
The
timing of the rehearsal also matters (don’t study things after you know
them). If you study and study and don’t remember all of the
material
equally well, you might be using a poor strategy for rehearsal.
There
will be more to the answer to this soon.
B. Retrieval: What affects it? There are two kinds
of remembering. In recall, you have to completely reconstruct the
information (like an essay exam). For recognition, the
information
is presented with new information, and you have to pick it out (like a
multiple choice exam). Obviously, recall tasks are harder.
However, the same memory mechanisms might be used for both.
Let’s consider a rudimentary model of retrieval from long-term
memory.
There are automatic components of memory. One of these is
frequency.
People generally have a good idea how frequently they’ve encountered
something
even when they weren’t paying attention to frequency. Likewise,
people
are pretty good at remembering where things were located when they were
encountered. For example, people might not know which page number
an experiment was on, but they can remember that it was on the left
page,
about halfway down. People also seem to automatically encode some
index of familiarity. This might be a result of processing.
For example, try to resolve the meaning of this sentence:
(1) The old man boats made of wood.
If you encounter this again, you shouldn’t need to spend so much time
figuring it out. This ease of processing might make you think the
sentence is more familiar than this one:
(2) The horse raced past the barn fell.
The same thing applies to reading words, but it’s less dramatic.
Resolving the sentences above takes time that’s measurable in
seconds.
Getting the meaning of “artichoke” when it’s presented at random might
happen in half a second, but it’s harder than retrieving the meaning of
“the.” So, if you see “artichoke” again, it should feel more
familiar
because it’s less difficult to access (you just figured it out a short
time ago).
Familiarity is automatically encoded, and it’s automatically
accessed.
That’s the first step in our model. You compute familiarity and
see
what the result is. If familiarity is high, then you have to do
more
work to retrieve the item (high familiarity means you might be able to
get something). If familiarity is low, there’s no need to try
retrieval
because there’s probably nothing there.
The second step is effortful retrieval. If it’s recall, you have
to construct the cues you use to find the item. These cues can be
things like “we heard about it on the day it snowed,” or they can be
related
to the meaning of what you’re trying to retrieve “this person tested
the
duration of short-term memory.” You put all of your cues
together,
and then pass them through memory to see if anything similar is in
there.
If you find something, that’s what you recall. To the extent that
you get good cues, recall will be successful.
You can improve recall by mixing up the cues. A popular technique
in interviewing witnesses is the cognitive interview. People are
asked to reinstate the context (the room, the weather, their thoughts,
etc.), report everything, no matter how trivial (this provides more
potential
cues), recall in a variety of orders, and take different
perspectives.
This technique produces 47% more information (Fisher, Geiselman, &
Amador, 1989). Why? All of these tricks make more cues to
use
in searching during the effortful retrieval process.
For recognition, someone else constructs the cue (it’s the actual item
you saw before). You need to get the familiarity for each item
and
then try the item as a retrieval cue. If we make an item seem
more
familiar, you’re likely to “recognize” it later, even if it’s the wrong
item, because of its increased familiarity. This happens when
police
show people mug shots and then line-ups. The people in mug shots
look familiar, and can be falsely recognized later.
Elizabeth Loftus (as in Loftus, Burns, & Miller, 1978) has made
a career out of messing with witnesses. She’ll present a slide
show
of a car driving down a road. Then she’ll ask a bunch of
questions.
In one question, she’ll throw in a barn that wasn’t in the scene (“How
fast was the car going when it passed the barn?”). People who get
this question are more likely to remember a barn later. Its
increased
familiarity makes it easier to recognize, even though it was never
there.
One last touch of this. When people construct multiple choice
exams, they try to mess with your familiarity. The lures (wrong
answers)
will resemble the right answer to equate familiarity. This forces
you to rely instead on the effortful retrieval component, and that is a
better index of how much you’ve learned. For example, consider
these
two questions:
| Question 1 |
Question 2 |
| Peterson and Peterson found that the duration of short-term
memory
is: |
Peterson and Peterson found that the duration of short-term
memory
is: |
| a. 16 seconds |
a. 1 minute |
| b. 17 seconds |
b. 1 hour |
| c. 18 seconds |
c. 18 seconds |
| d. 19 seconds |
d. 1 day |
Guess which one’s harder?
We will see in a moment that the automatic component (familiarity)
is spared when people have head injuries that damage memory, but the
effortful
component (retrieval) is what gets damaged.
Demonstration: You can see retrieval in action by doing
the following. Write down as many of the 50 states as you
can.
Put a line on the page when you stop just slapping them down and start
having to think about them. You should see some strategies
emerge.
The first few will probably be familiarity or frequency based
(Tennessee).
Then you might try an alphabetical strategy or a geographic strategy.
Retrieval is also studied in the laboratory with tip of the tongue
states. You hear a
definition
(“What is the name of the instrument that uses the position of the sun
and the stars to navigate?”). Sometimes, people will know they
know
the word, but can’t say it. This is a tip of the tongue
state.
When this happens, we can try to cue them to see if we can get
retrieval
over the hump. I might say “It sounds like sixteen.” Or,
“It
starts with ‘S’.” Spelling and sound cues are most effective for
people in this state. (The word was “sextant”.)
So far, our discussion of retrieval has been driven by this two-stage
model (familiarity and retrieval). This should lead to
predictions
about how certain variables affect memory. In the next unit,
we’ll
do a lot more here, but let’s just get a flavor.
1. Retention interval. The longer you wait for the test,
the less you’ll remember. Ebbinghaus memorized lists of nonsense
syllables (“NAX,” “POR,” “WEQ,” etc.). He found that most
forgetting
has happened after about five days. So, you forget pretty much
all
you’re going to forget in the first five days. Unfortunately, you
forget almost everything in the first five days, so there’s not a lot
to
be proud of. Our model would claim that this is due to
familiarity.
With more time the effort you spent on the first attempt to process has
faded (due to interference or decay), so you don’t have that to go
by.
Also, it gets harder to construct good cues for the effortful part.
2. List length. All things being equal, the more you try
to learn, the less you’ll remember. This could be due to build-up
of proactive interference, which might cause decreased familiarity
(because
there’s so much similar stuff). Or, the cues might be less
effective
because it’s hard to get a unique cue for each item (cue overload).
I'm going to discuss long term recency as an illustration of the "too
much for each cue" problem and how context and cues can make a
difference.
Demonstration: This is based on Bjork and Whitten
(1974).
Present a list of 10 word pairs for two seconds per pair.
Instruct
participants to rehearse only the current word pair. Have 12
seconds of multiplication problems before the first
item and between all items. Have 20 seconds after the last
item.
Free recall all 20 words. Plot recall to see if we get a primacy
and recency effect.
Bjork and Whitten found that the long-term recency effect was
different
from regular recency. This will take some thinking-back.
Glanzer
and Cunitz showed that having a 30 second distraction period after the
list eliminated recency. Bjork and Whitten replicated this
condition
in their study. The 0+0 people had a regular free recall
experiment.
The 0+30 people had a regular experiment, plus 30 seconds of
distraction.
The 0+30 people had no recency, the 0+0 people did. The bottom
half
shows the time in the recall task the people wrote down the
words.
Lower numbers means earlier. The 0+0 people recalled the recency
part really early, as if they were dumping out short-term memory.
The 0+30 people didn't write the recency words earlier, and didn't
remember
them as well.
The real question has to do with the other condition. In 12+0,
people had 12 seconds of distraction after each item, except there was
no distraction after the last item. In 12+30, people had 12
seconds
between items, plus another 30 seconds at the end. In both cases,
you get a recency effect . Long-term recency isn't affected by a
30 second counting backwards period. Regular recency is.
Whether or not we expect a recency effect is a function of the
interpresentation interval (IPI) (the time between items) and the
retention interval (RI) (how long you wait to recall). Here's the
function:
Task
|
IPI
|
RI
|
Ratio (IPI/RI)
|
Expect recency?
|
Standard free recall
|
Short (3 s)
|
Short (3 s)
|
Large
|
Yes
|
Glanzer and Cunitz (1966)
increased spacing
|
Longer (6-9 s)
|
Short (3 s?)
|
Large
|
Yes
|
Glanzer and Cunitz (1966) 30 s
counting backward
|
Short (3 s)
|
Long (30 s)
|
small
|
No
|
Bjork and Whitten (1974) 12 + 0
|
Long (12 s)
|
Short (approx. 0)
|
Large
|
Yes
|
Bjork and Whitten (1974) 12 + 30
|
Long (12 s)
|
Long (30 s)
|
Moderate
|
Yes
|
Glenberg, Bradley, Kraus, and Renzaglia (1983) present a chart showing
this relationship. Why does it work like this? Glenberg, et
al. argue in favor of a contextual explanation. The idea is that
there is a continually changing context in the experiment. The
context can be from the environment (PowerPoint, blower), the cognitive
and affective state (here to get test grade back, bored), and the
experimental task (I wish this was Psychosex). Some parts of the
context are changing faster than others. When you have a short
IPI and short RI, the recent items share context with the test and that
context can be used to help retrieve them. When the IPI is short
and the RI gets longer the test context is less similar and is a less
good cue. So, short IPI short RI gives you recency, short IPI
long RI reduces it. When IPI is long a similar pattern emerges
(I'll go over the chart in class).
All of this is to get to the point that the context can matter.
Longer lists at one sitting provide less variable contexts and give you
fewer potential retrieval cues.
3. Serial position. Remember the Glanzer and Cunitz work
with free recall. The position in the list you learn will affect
memory. First items are pretty good (primacy) and last items are
really good (recency), the rest are pretty crappy. Primacy is due
to rehearsal, which could affect familiarity by giving you more
practice.
Recency is discused above.
4. Type of test. Recognition tests are easier than recall
tests. Recognition tests provide you with the cues. Recall
tests don’t. Constructing good cues is most of the work.
One last bit here: Glenberg and colleagues have looked at the
effect of suppression on recall. They asked participants to
recall
obscure facts (“Is Kiev in the Ukraine?”). They surreptitiously
videotaped
the participants to see if they closed their eyes or looked away.
The harder the recall (indexed by more time trying or errors), the more
likely people were to look away. The hypothesis is that memory is
driven most by what’s presently in the environment (what it’s good for
is telling you what to do now). To kick memory out of your
present
environment you have to suppress the environment to make new
cues.
So, getting in a quiet place with few distractions may also help.
I can add some to the answer to our questions:
1. Why is it hard to learn some stuff after studying? These
factors. You have to have a good chance of experiencing
familiarity or constructing a good cue. Some stuff doesn't seem
to get in because you failed to do that.
2. Where did Calculus go? It's probably in there, but the
right cue is hard to come by.
Top
IV. The parts. We’ve been treating long-term memory
as a unitary thing. In reality, it’s probably not. Tulving
(starting in 1972) is an advocate of multiple memories. He looks
at neuropsychological data and data from experiments to conclude that
types
of memory are separate. A partial model is presented below:
A. Declarative memory. You can declare these (verbalize
them). Also called explicit memory.
1. Semantic memory: Facts. They’re processed,
compiled
knowledge. You don’t know where you heard them, you just know
them.
2. Episodic memory: Autobiographical information.
Organized around time and around you as the experiencer of them.
Everything starts here and some stuff can migrate into semantic.
So far this is what we've been discussing.
B. Non-declarative memory. You can’t declare these, you
might not even know about them. Also called implicit memory.
1. Procedural: How to do things.
2. Implicit: The residual effects of processing
stuff.
This would be familiarity in our model.
C. Declarative vs. non-declarative: Declarative memories
come with a feeling of remembering, you know when you’re having them,
and
they can be damaged by brain damage. Non-declarative memories
happen
without awareness, last a long time, and can be spared even when
declarative
is wiped out. Note the similarity between non-declarative memory
and automatic processing.
D. Are there different memories or different processes?
Tulving likes different memories. Jacoby argues for process
(Jacoby
& Dallas, 1981). Explicit memories (recall and recognition)
are
conceptually driven, and are accessed with recall strategies.
They’re
likely to be episodic memory. Implicit memories are procedural,
data
driven (familiarity) and are accessed by indirect tasks (fragment
completion).
Affect familiarity by manipulating modality. If you heard the
words, the written form won’t be as familiar and vice versa. This
should affect indirect memory, but not direct memory. It does.
Affect retrieval by having people solve anagrams (EMTLA) or read
(METAL).
The anagram should improve direct measures over reading, but shouldn’t
affect indirect measures. It does just this.
So, instead of two kinds of memory, it looks like two kinds of
processing.
Evidence for separate kinds of memory comes from amnesia. People
can lose declarative but not procedural. If it’s just processing,
this is hard to explain. Squire has shown that damage to the
hippocampus
is what makes it hard to form new declarative memories without harming
the formation of procedural memories (HM).
Top
V. Segue into a new idea. Let’s begin the transition
to a more modern approach to the cognitive system.
A. Segue. Return your attention to the old box model.
We’ve now gone over all of the boxes. But, we’ve diversified a
bit.
Our new model looks something like this:
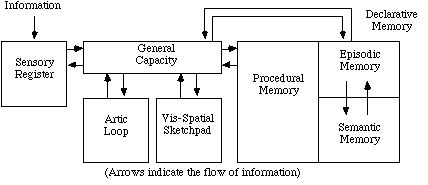
Attention can operate pretty much anywhere. Processes (like
pattern
recognition) take place primarily in working memory. This is a
complicated
system, and we have pretty good support for each of the
divisions.
But, does that mean memory really works this way?
A different approach is to look at processing (instead of
representation).
What you do with information has a big impact on how well it’s
remembered.
Let’s consider for a moment the extreme of this viewpoint: none
of
these memory divisions are real. Instead, memory is entirely a
function
of processing. If you do very low level tasks (basic sensation, a
little perception), then you get what looks like a sensory
register.
If you do more, you get short-term memory, etc.
Levels of processing: Material can be processed at a shallow
level (attention to physical features) up to a deep level (attention to
meaning). Generally, the deeper the processing the better your
memory
will be.
B. Kinds of processing.
1. We’ve looked at the role of rehearsal in memory. Rundus’
data indicates that more rehearsal leads to better memory, and this
rehearsal
seems to be the source of primacy effects. But, is all rehearsal
the same? No. There are two types.
a. Type I rehearsal: This is called maintenance
rehearsal.
This is what you use when you’re trying to hold something in the
articulatory
loop temporarily (like a phone number). This type of rehearsal is
not likely to lead to lasting memory. When you stop maintaining
the
item, it goes away.
b. Type II rehearsal: This is called elaborative
rehearsal.
Instead of merely repeating the item, you try to elaborate it and
increase
the number of memory cues that can access it. You might use a
mnemonic
device or mental imagery. This kind of rehearsal leads to lasting
memories.
Let’s look at the effectiveness of maintenance rehearsal.
Demonstration: I'll present a memory task here to look at
the impact of increasing rehearsal.
Usually, more maintenance rehearsal won’t improve recall. Any
rehearsal is better than no rehearsal, but varying the amount won’t
help.
Our demonstration was a replication of a study by Craik and Watkins
(1973). They varied the rehearsal time from 0 to 12
seconds.
Over the course of the experiment, participants saw 27 lists. For
the overall recall, 0 seconds of rehearsal led to 12% recall, 12
seconds
led to 15% (not different). Again, increasing the amount of time
that you’re merely maintaining information is not going to improve
memory.
We can add more to the answer to the first question. No matter
how much you
study, if it’s just maintenance rehearsal, then you won’t get much out
of it.
2. If more maintenance isn’t going to improve memory, what
will?
Elaborative rehearsal.
CogLab: We'll look at our
data from the levels of processing demonstration.
Demonstration: I’m going to present a list of words.
I’ll also distribute a task sheet. For each word, you circle
“yes”
or “no” based on the question on your task sheet. We'll look at
the specific nature of the recall to see what we can find out about the
different approaches.
This demonstration replicates a study by Hyde and Jenkins (1969).
They had people make these same types of judgments. Their meaning
participants recalled 16.3 words out of 24. The ‘e’ people only
got
9.4. We know meaning people really attended to meaning because of
the clustering data. Meaning people had 68% clustering, ‘e’
people
only had 26%. (Note: Compare to our data.)
In the next set of notes we’ll fully explore this focus on processing
over representation. We’ll try to develop a processing account of
memory.
Top
Cognitive Psychology Notes 6
Will Langston
Back to Langston's Cognitive Psychology
Page